Generalized Plackett-Luce Model
Generalized Plackett-Luce model (GPL) is a model for rank-ordered data. It includes the ties presented.1 This blog tries to illustrate such model with my own understandings.
Recently, a paper shows such model is suitable for modeling single cell transcriptomic data, due to its scalability for training virtual cell model.2
First, several notations with examples:
Buckets and ties
A group of entities:
\[K = \{1, 2, 3, 4, 5\}\]Then let’s rank them with orderings:
\[Y = (1, 2, 4, 5, 3)\]Here, \(Y\) is the ordered version of \(K\).
\[S = (1,2,3,3,4)\]\(S\) is the ordered set indicator. In \(S\), there are three buckets.
How many possible buckets for \(K\)? This is the Fubini numbers:
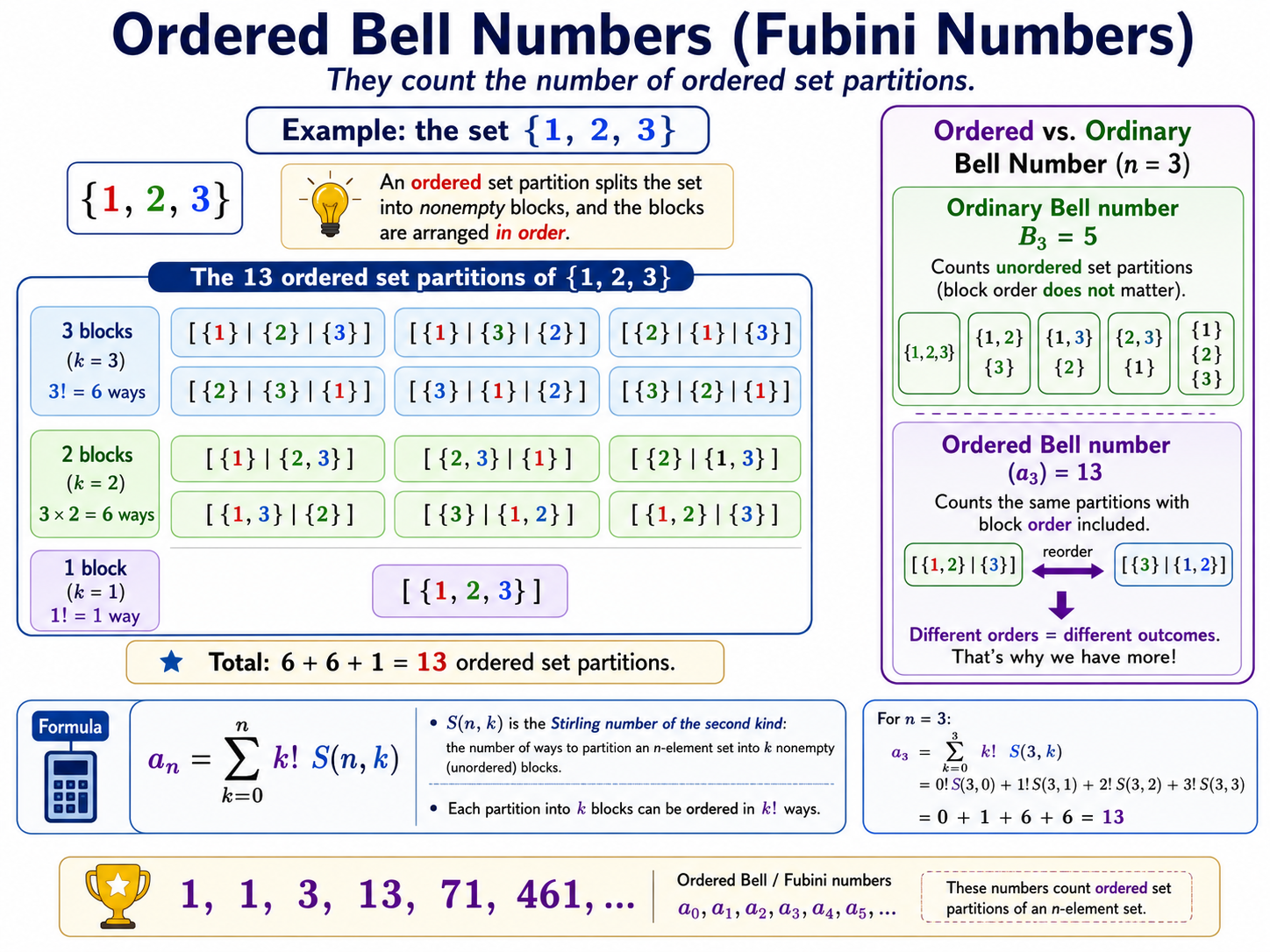
See here in \(Y\), entities 4 and 5 in \(K\) are tied. Swapping 4 and 5 does not change the information. Then we define the tie indicator:
\[t_{j} = I(S_{j} = S_{j+1})\] \[T = (0,0,1,0)\]How many possible tie patterns?
\[2^{k-1}\]Tie patterns are fewer than bucket orders.
Rank ordering
Weak ordering allows ties.
Suppose we have \(M \le k\) entities:
- Complete: ordering of all \(M\) entities.
- Top-m: ordering of \(m\) entities, where \(m < M\).
GPL model can be applied in both cases.
Plackett-Luce model
\[Pr(W_{y_{1}} < W_{y_{2}} < ... < W_{y_{k}}|\lambda) = \Pr(Y = y \mid \lambda) = \prod_{j=1}^{K-1} \frac{\lambda_{y_j}} {\sum_{\ell=j}^{K} \lambda_{y_\ell}} .\]\(\lambda\) here represents the possibility of an entity being ranked ahead.
\[\frac{\lambda_{y_j}} {\sum_{\ell=j}^{K} \lambda_{y_\ell}}\]represents entity \(y_i\) being ranked ahead.
\[W_k \overset{\text{indep.}}{\sim} \operatorname{Exp}(\lambda_k)\]Side note: exponential distribution
Density function for exponential distribution:
\[f(w) = \lambda e^{-\lambda w}, w>0\]Considering any time but with item \(i\) ordering before others \((j)\):
\[i: f_{i}(t) = \lambda_{i}e^{-\lambda_{i}t}\] \[j: P(w_{j} > t ) = e^{-\lambda t}\] \[\begin{aligned} P(i\ \text{first}) &= \int_{0}^{\infty} \lambda_i e^{-\lambda_i t} \prod_{j\ne i} e^{-\lambda_j t} \,dt \\[1.2em] &= \int_{0}^{\infty} \lambda_i e^{-\left(\sum_k \lambda_k\right)t} \,dt \\[1.2em] &= \lambda_i \int_{0}^{\infty} e^{-\left(\sum_k \lambda_k\right)t} \,dt \\[1.2em] \int_{0}^{\infty} e^{-at}\,dt &= \frac{1}{a} \\[1.2em] P(i\ \text{first}) &= \lambda_i \frac{1}{\sum_k \lambda_k} = \frac{\lambda_i}{\sum_k \lambda_k}. \end{aligned}\]Generalized Plackett-Luce model
Allowing ties in the order replaces the exponential distribution with a geometric distribution:
\[\Pr(W_k = w) = (1-\theta_k)^{w-1}\theta_k, \qquad w \in \{1,2,3,\ldots\}\]Reference
Enjoy Reading This Article?
Here are some more articles you might like to read next: